

In questi anni stiamo vedendo un incremento verticale delle strutture ad alta efficacia, sia in termini di performance che di affidabilità, intesa come raggiungibilità del servizio. È evidente, e permettetemi di dire che è bello, che ciò arrivi anche alle piccole infrastrutture e non sia più riservata alle grandi infrastrutture, scale-up o startup di grandi dimensioni. Così come si continua a lavorare per diminuire i tempi di caricamento e risposta, eliminare i downtime ed i single point of failure è altrettanto importante. La High Availability (che tradurremmo come Elevata Disponibilità) è una qualità che possiamo attribuire alle infrastrutture che scalano efficacemente per rispondere proprio a queste due necessità e non solo.
Vediamo insieme cosa significa e in cosa consiste, e soprattutto come possiamo migliore la nostra, anche piccola, infrastruttura.
Che cos’è la High Availability?
Partiamo dal concetto di availability, cioè di disponibilità: com’è facile capire intendiamo semplicemente il fatto che un servizio sia attivo e raggiungibile e quanto esso impieghi a rispondere alla nostra richiesta. La High Availability è proprio questa: la capacità di un sistema o di un componente di assicurare una performance alta senza interruzioni di sorta in un dato periodo di tempo. In due parole, un servizio sempre attivo, senza interruzioni, da Amazon – che quantifica in 100milioni di dollari un secondo di downtime durante il Prime Day – sino a strutture sensibili come gli ospedali.
Misuriamola
Per spiegare la disponibilità, un buon modo è usare le percentuali: spesso infatti ci troviamo davanti alle percentuali di uptime di un sistema rispetto ad un periodo di tempo, dove un valore del 100% significa che il sistema non fallisce mai. Generalmente questa percentuale viene calcolata su base annua, e ciò significa che se qualcuno vi garantisce il 99% di uptime, vi sta dicendo anche che potrebbero esserci 3,65 giorni di downtime in un anno (ovvero l’1%). Dato che quasi quattro giorni di servizio interrotto sono un’enormità, è per questo che spesso sentirete parlare di “nines”. Cioè di quanti “nove” dopo la virgola del 99% ci sono.
Questi numeri tengono conto di tutti i fattori, inclusa, ad esempio, la manutenzione programmata e quella non programmata.
Perché è importante
Quando creiamo una infrastruttura robusta, minimizzare il downtime e le interruzioni dovrebbe essere sempre una priorità. Per quanto possiamo scrivere del buon codice e fare un buon setup dell’infrastruttura, però i problemi che tirano giù la nostra infrastruttura accadono: come si dice, shit happens. Implementare un sistema ad Alta Disponibilità per la nostra infrastruttura è una strategia ottimale per ridurre l’impatto delle interruzioni. Potremmo fare anche di più: i sistemi High Availability dovrebbero reagire automaticamente alle interruzioni. Vediamo quali sono le regole fondamentali.
Com’è fatto un sistema High Availability?
Come accennato, uno degli obbiettivi della High Availability è rimuovere, per quanto possibile, i single point of failure, quelli che in italiano potremmo definire gli anelli deboli della catena. Un componente del nostro stack tecnologico il cui fallimento interromperebbe l’intero servizio. In linea generale, qualsiasi componente strategico per il sistema che non ha ridondanza è considerabile come un single point of failure.
Quindi, quando progettiamo la nostra infrastruttura, la prima regola è che ogni singolo livello deve essere implementato in modo ridondante, banalmente ogni sistema deve avere un gemello. Facciamo un esempio: immaginiamo di avere due web server perfettamente ridondanti sotto un load balancer. Il traffico dai client degli utenti verrà instradato dal load balancer ad uno dei due server, quindi se uno dei due va giù, il load balancer invierà tutto il traffico all’altro web server ancora online.
Con questo tipo di infrastruttura, il layer dei web server non è un single point of failure perché:
- ci sono componenti ridondanti che si occupano dello stesso task
- il meccanismo a monte (il load balancer) è capace di determinare il failure dei web server e adattarsi automaticamente
Tutti contenti, ma che succede se è il load balancer and andare giù?
Non è raro che succeda nella vita reale, ma il load balancer rimane un single point of failure della nostra infrastruttura. Eliminare questo singolo punto, potrebbe essere complicato: anche se possiamo affiancare un secondo load balancer per ottenere la ridondanza non c’è un chiaro punto a monte dei load balancer nel quale possiamo gestire i downtime.
Questo ci porta al fatto che la ridondanza in sé non può garantirci la High Availability. Dobbiamo per forza mettere in pratica un meccanismo che si accorga del failure ed intervenga automaticamente quando uno dei componenti dell’infrastruttura diventa indisponibile.
La failure detection ed il recovery automatico possono essere implementati usando un approccio top-down: i livelli più in alto diventano responsabili del monitoraggio dei livelli immediatamente sotto. Nel nostro esempio precedente, il load balancer è ovviamente in alto. Quando uno dei web server diventa indisponibile, il load balancer gli non manderà più traffico.
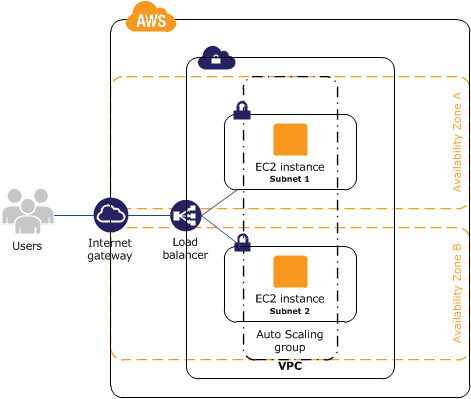
AWS – Increase the Availability of Your Application on Amazon EC2
Come abbiamo già detto, rimane il caso nel quale è proprio il load balancer a non funzionare. Affiancargli un secondo load balancer non risolverebbe del tutto il problema: se creassimo, ancora prima dei load balancer, un server di controllo avremmo creato un nuovo single point of failure.
In questo scenario, è necessario un approccio distribuito. Più nodi (ovvero server) ridondanti devono essere connessi insieme per creare dei cluster dove ogni punto deve essere capace di intervenire in caso di failure detection.
Per il caso dei load balancer, poi, c’è un ulteriore complicazione, data dal come i DNS funzionano. Fare il recover di un load balancer significherebbe (in alcuni casi) cambiare il record DNS per far puntare lo stesso dominio ad un nuovo IP, quello del secondo load balancer. Un cambio del genere comporta l’attesa della propagazione a livello mondiale dei DNS, provocando un downtime considerevole.
Le moderne infrastrutture cloud offrono un sistema affidabile che offre la flessibilità di rimappare gli indirizzi IP “al volo” puntandoli verso diversi servizi, eliminando quindi il tempo di propagazione di cui parlavamo in precedenza. Con l’utilizzo di questi IP flessibili, semplicemente, lo stesso indirizzo IP viene puntato verso il servizio (il web server rimasto in piedi) ridondante. Il dominio, sarà sempre associato a questo IP, che “si muoverà” tra i servizi. AWS Elastic IP, Microsoft Azure Load Balancer e Google Cloud Floating IP fanno proprio questo.
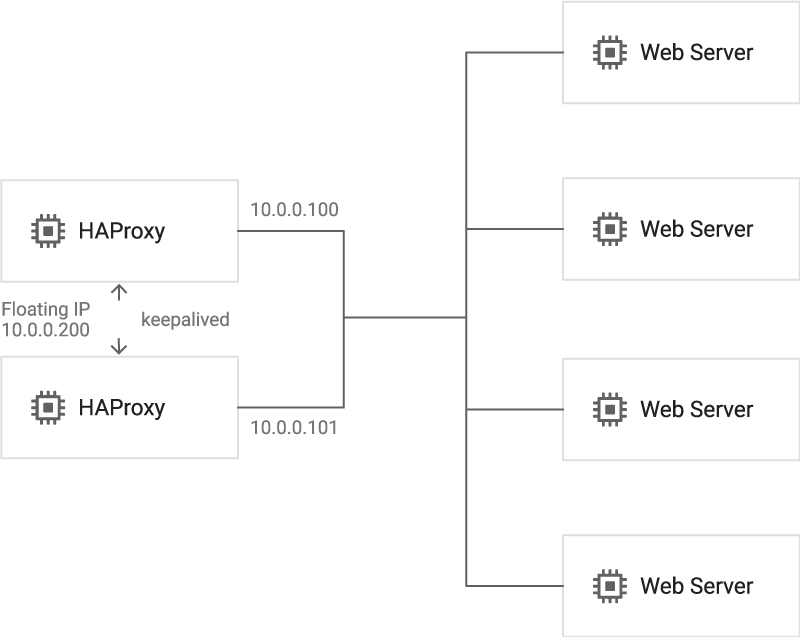
Google Cloud Platform – Best Practices for Floating IP Addresses
Un fattore importante da tenere in considerazione, poi, è la geografia: cioè in quale datacenter o zona del mondo girano i nostri servizi. Amazon Web Services, ad esempio, ha fatto scuola con i suoi servizi Multi-AZ, ovvero la possibilità di distribuire sistemi gemelli (e non solo) in giro per tutti i suoi datacenter nel mondo. Senza andare troppo nello specifico, ciò ci protegge dai failure che potrebbero capitare all’intero datacenter. Sembra una eventualità remota ma, ad esempio, nel 2017 il datacenter Ovh di Strasburgo venne tirato giù completamente per un problema al sistema di raffreddamento per quasi 3 giorni.
La soluzione potrebbe essere quella di replicare i servizi in zone differenziate.
Quali sono i componenti da tenere in considerazione?
Ci sono vari componenti che possono essere tenuti in considerazione per creare un’infrastruttura considerabile High Availability. Più che sul software, essa dipende da fattori come:
- Provider: utilizzare tutti i servizi dello stesso provider, problemi legati a quest’ultimo potrebbero oscurare il nostro intero servizi, mettendo tutte le uova in un paniere.
- Ambiente: se tutti i nostri server sono locati nella stessa area geografica, qualche condizione ambientale (terremoto, allagamento, etc.) potrebbe portare tutti i sistemi giù. Avere server in datacenter indipendenti geograficamente incrementerà la disponibilità.
- Hardware: affidarsi a server che sono ridondanti a livello hardware ci tiene coperti rispetto a failure che possono riguardare i dischi, l’alimentazione, etc.
- Dati: anche se i dati seguono le regole generali, è bene creare grande ridondanza sia per il database che lo storage di oggetti statici semplici (immagini, etc.).
- Network: anche se rare, le indisponibilità di rete rappresentano ancora un possibile point o failure.
Conclusioni
L’High availability è un fattore strategico fondamentale nell’implementazione di un servizio, per assicurare agli utenti la sua continuità e disponibilità nel tempo. Anche se la sua implementazione può sembrare complessa, porterà sicuramente grandi benefici, anche alle piccole infrastrutture. Il cloud moderno, attraverso i grandi provider ci permette di costruire un’infrastruttura di grande qualità anche con budget ridotti, per poi scalare in modo omogeneo con il crescere degli utenti del nostro servizio.

